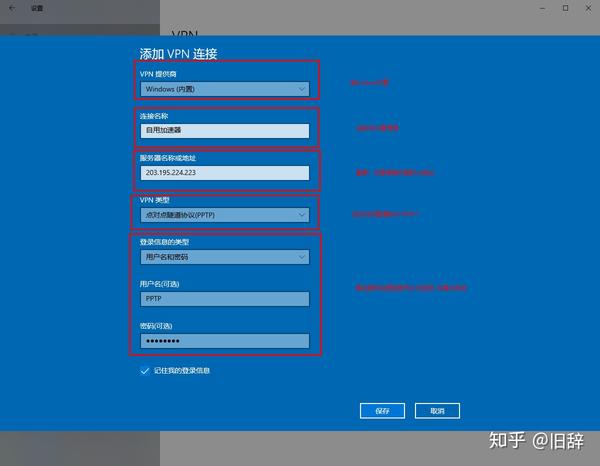
2024tokenpocket钱包官网
tokenization的含义-token physicalism
2删除停止词Stop Words Removal在标记化之后,下一步自然是删除停止词这一步的目标与上一步类似,也是将文本数据转化为更容易处理的格式这一步会删除英语中常见的介词,如“and”“the”“a”等之后在分析数据时,我们就能消除干扰,专注于具有实际意义的单词了通过比对定义列表中的。
n 表征代币记号 adj 象征的表意的作为对某事的保证的 vt 象征代表 词组短语by the same token 同样地出于同样原因 as a token of 作为?的标志 token ring 令牌环一个环状的区域网路in token of 表示作为?的标志 by this token 由此看来。
Stopwords Corpus除了常规的文本文字,另一类诸如介词,补语,限定词等含有重要的语法功能,自身却没有什么含义的词被称为停用词stop wordsNLTK 所收集的停用词语料库Stopwords Corpus包含了 来自 11 种不同语言包括英语的 2400 个停用词 32 NLTK 命名约定 在开始利用 NLTK 处理我们的任务以前,我们先来。

数据预处理在分析之前,需要对数据进行预处理这包括清洗数据,去除无关信息,如广告版权信息等然后,将文本数据转换为可分析的格式,例如标记化tokenization,即将文本分割成单词短语或其他有意义的单元特征提取特征提取是识别模式的关键步骤你可以提取多种特征,如词频ngrams连续的。
BPE概述 BytePairEncoding是用于解决未登录词的一种方法首先简单提一句什么是未登录词,未登录词可以理解为训练语料库中没有出现的,但是在测试语料库中出现的词我们在处理NLP任务时,通常会根据语料生成一个词典,把语料中词频大于某个阈值的词放入词典中,而低于该阈值的词统统编码成quot#UNKquot这。

1标记化Tokenization标记化指的是将文本切分为句子或单词,在此过程中,我们也会丢弃标点符号及多余的符号这个步骤并非看起来那么简单举个例子纽约New York一词被拆成了两个标记,但纽约是个代名词,在我们的分析中可能会很重要,因此最好只保留一个标记在这个步骤中要注意这一点。
token 读音英 #39t#601#650k#601n 美 #39tok#601nn 表征代币记号 adj 象征的表意的作为对某事的保证的 vt 象征代表 词组短语by the same token 同样地出于同样原因 as a token of 作为?的标志 token ring 令牌环一个环状的区域网路in token of。